原文链接:https://mp.weixin.qq.com/s/SHzgUvFNXcCWIBN15TpbkQ
内容生产,特别是创意工作,一向被认为是人类的专属和智能的体现。牛津大学计算机学院院长迈克尔·伍尔德里奇 2019 年写作的《人工智能全传》一书中,“撰写有趣的故事”被列为人工智能“远未实现”的任务之一。
如今,AI 正大步迈入数字内容生产领域。AIGC(AI Generated Content)不仅在写作、绘画、作曲多项领域达到“类人”表现,更展示出在大数据学习基础上的非凡创意潜能。2023 年 3 月 15 日,多模态信息处理标杆 GPT-4 模型正式发布,使生成内容的准确度及合规性进一步提升。数字内容生产的人机协作新范式正在形成,创作者和更多普通人得以跨越“技法”和“效能”限制,尽情挥洒内容创意。
也有人担忧,AI 是否会让创作者们集体“失业”,甚至让“创作”本身走向衰颓,就像机械复制时代的艺术品可能失去“灵晕”那样。换言之,AIGC 的流行给了我们一个重新审视“创作”是什么,是否为人所独有这些问题的机会。
本文将分析 AIGC 改变数字内容创作的现状、关键突破和挑战,并尝试探讨以上问题。
数字内容正迈入强需求、视频化、拼创意的升级周期,AIGC 恰逢其会。线上生活成为常态,一方面,用户创作内容大幅解放生产力,例如短视频就是将原本需要长制作周期、高注意投入的视频,变成了可以源源不断产出的“工业品”和“快消品”;另一方面,作为核心的创意仍旧稀缺,需要新的模式辅助创作者持续产生、迭代和验证创意。种种因素,都需要更加低成本、高效能的新工具与方式。
AIGC 正在越来越多地参与数字内容的创意性生成工作,以人机协同的方式释放价值,成为未来互联网的内容生产基础设施。
从范围上看,AIGC 逐步深度融入到文字、代码、音乐、图片、视频、3D 多种媒介形态的生产中,可以担任新闻、论文、小说写手,音乐作曲和编曲者,多样化风格的画手,长短视频的剪辑者和后期处理工程师,3D 建模师等多样化的助手角色,在人类的指导下完成指定主题内容的创作、编辑和风格迁移工作。
从效果上看,AIGC 在基于自然语言的文本、语音和图片生成领域初步令人满意,特别是知识类中短文,插画等高度风格化的图片创作,创作效果可以与有中级经验的创作者相匹敌;在视频和 3D 等媒介复杂度高的领域处于探索阶段。尽管 AIGC 对极端案例的处理、细节把控、成品准确率等方面仍有许多进步空间,但蕴含的潜力令人期待。
从方式上看,AIGC 的跨文字、图像、视频和 3D 的多模态加工是热点。吴恩达(Andrew Ng)认为多模态是 2021 年 AI 的最重要趋势,AI 模型在发现文本与图像间关系中取得了显著进步,如 OPEN AI 的 CLIP 能匹配图像和文本,Dall·E 生成与输入文本对应的图像;DeepMind 的 Perceiver IO 可以对文本、图像、视频和点云进行分类。典型应用包括如文本转换语音 TTS(Text To Speech)、文本生成图片(Text-to-Image),广义来看 AI 翻译、图片风格化也可以看作是两个不同“模态“间的映射。
 原图,AIGC 的典型场景及发展趋势,来自红杉资本
原图,AIGC 的典型场景及发展趋势,来自红杉资本

使用有道智云 AI 翻译后的结果
AIGC 对创作者的解放体现在:“只要会说话,你就能创作”,无需懂得原理,不用学习代码,或者 Photoshop 等专业工具。创作者以自然语言向 AI 描述脑海中的要素甚至想法(术语是给出“prompt”)后,AI 就能生成对应的结果。这也是人机互动从打孔纸带,到编程语言,图形界面后的又一次飞跃。
自然语言是不同数字内容类型间转化的根信息和纽带,比如“猫”这个词语就是加菲猫的图片,音乐剧《猫》和无数内容的索引,这些不同的内容类型可以称为“多模态”。
AIGC 此轮浪潮,最大底层进化就在 AI 对自然语言“理解”和“运用”能力的飞跃,这离不开 2017 年 Google 发布的 Transformer,它开启了大型语言模型(Large Language Model,简称 LLM)时代。有了这一强大的特征提取器,后续的 GPT、BERT 等语言模型突飞猛进,不仅质量高、效率高,还能以大数据预训练+小数据微调的方式,摆脱了对大量人工调参的依赖,在手写、语音和图像识别、语言理解方面的表现大幅突破,所生成的内容也越来越准确和自然。
但大模型意味着极高的研究和使用门槛,例如 GPT-3 有 1750 亿参数量,既需要大算力集群也不向一般用户开放。2022 年,部署在 Discord 论坛上、以聊天机器人形式提供的 midjourney 成为了第一个用户友好型 AIGC 应用,带来 AI 绘画热潮,一位设计师用其生成的图片甚至在线下比赛中获奖。

引发争议的 AI 辅助创作作品
使用简单文字即可交流的低门槛,类似搜索引擎的使用方式,一下子点燃了普通用户对 AI 使用的热情。紧接着,基于扩散模型(Diffusion Models)的一系列文本生成图片(Text-to-Image)产品,如 Stable Diffusion 等,把 AI 绘画从设计圈带向大众。开源的 Stable Diffusion 仅需一台电脑就能运行,截至 2022 年 10 月已有超过 20 万开发者下载,累计日活用户超过 1000 万;而面向消费者的 DreamStudio 则已获得了超过 150 万用户,生成超过 1.7 亿图片。其惊艳的艺术风格、以及图像涉及的版权、法律等问题也引发了诸多争议。
Diffusion 的震撼感还没消散,ChatGPT 横空出世,真正做到和人类“对答如流”,能理解各式各样的需求,写出回答、短文和诗歌创作、代码写作、数学和逻辑计算等。不仅如此,人类反馈强化学习(RLHF)技术让 ChatGPT 能持续学习人类对回答的建议和评价,朝更加正确的方向前进,因此以不到 GPT3 的 1%的参数实现了极佳的效果。尽管 ChatGPT 仍存在一些缺陷,例如引用不存在的论文和书籍、对缺乏数据的问题回答质量不佳等,但它仍然是人工智能史上的里程碑,并上线两个月后用户数突破 1 亿,成为史上用户数增长最快的消费者应用。
在文、图、视频后,数字技术演进的重要方向是从“在线”走向“在场”,AIGC 将成为打造 3D 互联网的基石。人们将在在虚拟空间构建仿真世界,在现实世界“叠加“虚拟增强,实现真正的临场感。随着 XR、游戏引擎、云游戏等等各种交互、仿真、传输技术的突破,信息传输越来越接近无损,数字仿真能力真假难辨,人类的交互和体验将到达新阶段。
目前 AIGC 在 3D 模型领域还处于探索阶段,一条路径是以扩散模型为基础分两步走:先由文字生成图片,再生成包含深度的三维数据。谷歌和英伟达在这一领域较为领先,先后发布了自己的文字生成 3D 的 AI 模型。但从生成效果看,距离现在人工制作的 3D 内容的平均质量还有距离;生成速度也未能尽如人意。
2022 年 10 月,谷歌率先发布了 DreamFusion,但其缺点也很显著,首先扩散模型仅对 64x64 的图像生效,导致生成 3D 的质量不高;其次场景渲染模型不仅需要海量样本,也在计算上费时费力,导致生成速度较慢。随后,英伟达发布了 Magic3D,面对提示语“一只坐在睡莲上的蓝色毒镖蛙”,用大约 40 分钟生成了一个带有纹理的 3D 模型。相比谷歌,Magic3D 生成速度更快、效果更好,还能在连续生成过程中保留相同的主题,或者将风格迁移到 3D 模型中。
 Magic3D(第 1、3 列)与 DreamFusion(第 2、4 列)对比
Magic3D(第 1、3 列)与 DreamFusion(第 2、4 列)对比
第二条路径是借助 AI 来“合成”不同视角下同一物品的照片,从而直接生成 3D。英伟达在 2022 年 12 月的 NeurIPS 上展示了 生成式 AI 模型——GET3D(Generate Explicit Textured 3D 的缩写),可根据其所训练的建筑物、汽车、动物等 2D 图像类别,即时合成 3D 模型。和上文中的输出物相比,模型和纹理更精细,更采取了一般 3D 工具的通用格式,能直接用到构建游戏、机器人、建筑、社交媒体等行业设计的数字空间,比如建筑物、户外空间或整座城市的 3D 表达。GET3D 在 英伟达 A100 GPU 上训练而成,使用了不同角度拍摄的约 100 万张照片,每秒可生成约 20 个物体。结合团队的另一项技术,AI 生成的模型能够区分出物体的几何形状、光照信息和材质信息,使可编辑性大幅加强。

NVIDIA GET3D 基于 AI 生成的模型示例
尽管如此,AIGC 在 3D 侧的能力,距离打造 3D 互联网仍有不小的距离。而游戏中较为成熟的程序化内容生成(PCG,Procedural Content Generation)技术,可能是 AIGC 迈过深水区的一大助力。
从技术路径上,AI 生成 3D 难以沿用“大力出奇迹”的老办法,即单靠喂给 AI 海量的输入来提升效果。首先,信息量不同,一张图片和一个 3D 模型相比相差一个维度,体现在存储上就是数据量级不同;其次,图片和 3D 的存储及显示原理不同,如果说 2D 是像素点阵在显示器的客观陈列,3D 则是实时、快速、海量的矩阵运算,就像对着模型在 1 秒内进行几十次“拍照”。为了准确计算得到每个像素点,“渲染”在显示器上,需要考虑的因素至少有(1)模型几何特征,通常用几千上万个三角面来表示(2)材质特征,模型本身的颜色,是强反射的金属,还是漫反射的布料(3)光线,光源是点状的吗,颜色和强度如何。最后,原生 3D 模型的数据相对较少,仅游戏、影视、数字孪生等领域有少量积累,远不如已存在了数千年、可以以非数字化形态存在的图像那么多,例如 ImageNet 中就包含了超过 1400 万张图片。
用计算机帮助创作者这件事,游戏界已经探索了四十多年。用算法生成的游戏内容首次出现在1981 年的游戏 Rogue(Toy and Wichman)中,地图随机,每局不同。3D 时代,程序化生成技术大量应用于美术制作,因为其需要巨额时间和人力成本,以 2018 年发售的游戏《荒野大镖客 2》为例,先后有六百余名美术参与,历经 8 年才完成约 60 平方公里的虚拟场景。
程序化生成在效能和可控度上介于纯手工和 AIGC 之间。例如2016 年发布、主打宇宙探险的独立游戏《无人深空》(No Man's Sky),用 PCG 构造了一系列生成规则和参数,声称能创造出 1840 亿亿颗不同的星球,每个星球都有形态各异的环境和生物。

游戏《无人深空》中使用程序化生成的海洋生物示例
2022 年的 Epic 打造的交互内容《黑客帝国:觉醒》在最新虚幻引擎和程序化生成加持下,打造出栩栩如生、高度复杂的未来城市,共包括 700 万个美术资产,包括 7000 栋建筑、38000 辆可驾驶的车和超过 260 公里的道路,其中每个资产由数百万个多边形组成。
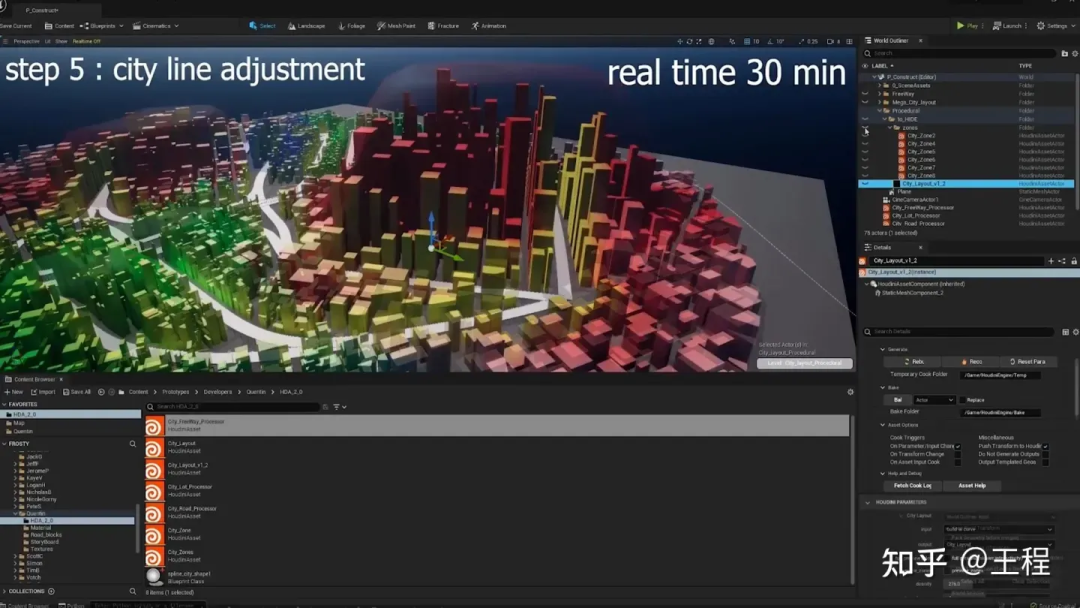
Epic 使用虚幻 5 引擎和程序化生成技术高效制作《黑客帝国:觉醒》中的庞大城市
程序化生成和 AI 的结合更成为热门学术领域,每年人工智能与游戏的顶级学会——IEEE Transactions on Games 都会为程序化生成开辟专门的讨论板块。剧情、关卡、场景、角色,每个板块都有大量的研究和实践成果在推进。
关于创作,有一句经典论断——天才是 99%的汗水,加上 1%的灵感。爱迪生认为那 1%的灵感最重要。AIGC 则向我们证明,99%的汗水能产生质变。善用 AI 的创作者,或许才是“完全体”。
首先,AI 和自然人的创作过程,没有那么大的差异:一部作品的诞生,一个作者的成长,都建立在大量对经典的观察、参照、模仿、提炼基础上,并非一蹴而就。而创新往往也有迹可循,或者是对主流的扬弃甚至反叛,或者是对多种元素的加成和融合。因此,如知识产权制度,也是在鼓励创作的基础上,给予贡献者以对等的奖励,而非一刀切地拒绝模仿。
其次,人作为创作核心这一点没有变化:AI 面向任务,人类面向创造。一方面,人类信息系统纷繁复杂,远非几个“prompt”输入就能概括。正如一位网友说,AI 代替不了我,因为它理解不了老板的需求。没有五年经验的乙方,也解读不来甲方口中的“要大气”。另一方面,AI 成长的养料仍然由人提供,AI 更可靠可信也依赖着人的使用与反馈。“断奶”于 2021 年的 ChatGPT 可不知道 2022 年世界杯的战果。
从实用的视角,AIGC 将赋予普通用户更多的创作权力和自由。从 PGC、UGC 到 AIGC 的发展路径可见,普通人越来越多的参与到创作之中,数字内容不仅呈现数量上的指数级增长,类型和风格也走向了更加包容和多元的生态。未来,用户可以使用手机拍摄的一系列照片,通过 AIGC 工具生成一个可以使用的 3D 渲染图。采用这种创造内容的方式,我们可以想象未来的数字空间将不再完全由开发人员构建,而是利用 AIGC 响应用户的输入按需生成。
AIGC 工具对专业人士的杠杆效应更显著:如果对普通人的增益是从 0 到 1,对专业人士则可能是从 1 到 10,使他们能集中精力处理更顶层、更有价值的事情:比如立意,风格,构图,元素组合和后处理,或者怎样在前期制作尽可能多样的 demo 来找寻更好的方案。运用 AI 也正成为新的职业能力,善于“施咒”的大触们前赴后继地开发着 AI 近乎无限的潜能,并社交平台上留下让人望洋兴叹的作品。
更长期看,创作和艺术的历史是螺旋上升的历史,是某一种风格数量极大丰富、质量巅峰造极之后的突破、突变与跨界,也是一个时代精神情感的凝结。我们有理由相信,AIGC 变革下创新依旧存在,甚至会加速发展。
参考:
NVIDIA 研究团队构建 AI 模型,为虚拟世界填充 3D 物体和人物,NVIDIA 英伟达微信公众号,
程序生成内容 PCG 十年,过去,趋势,未来 - Sindragosa 的文章 - 知乎
https://zhuanlan.zhihu.com/p/388666777
【译】无人深空的程序化生成 - 大雄的文章 - 知乎
https://zhuanlan.zhihu.com/p/82758631
开放世界技术整理 #40 黑客帝国觉醒:程序化生成城市 - 王程的文章 - 知乎
https://zhuanlan.zhihu.com/p/493739360
[2] 2019 年以来,韩国政府先后投入 66 亿、14 亿韩元,用于振兴游戏产业和支持移动游戏出海。
[3] 对未在韩设置经营场所但通过 Google Play 等在韩开展业务的,直接由 Google 征税 10%;没有实际办公场所的,需书面提交代理人信息,否则将会被处以最高 5 亿韩元、五年以上有期徒刑的处罚。

